티스토리 뷰
Abstract
- ChatGPT와 같은 모델? GUI를 이해하고 상호작용하는 데 어려움.
- GUI 이해와 탐색에 특화된 180억 개의 파라미터를 가진 Visual Language Model (VLM)인 CogAgent를 소개함
- CogAgent는 저해상도와 고해상도 이미지 인코더를 모두 활용하여 1120 x 1120 해상도의 입력을 지원하며, 작은 페이지 요소와 텍스트를 인식할 수 있음.
Introduction
- 대부분의 applications은 GUI를 갖추고 있어 언어 기반 agent가 처리하기 어렵다는 문제를 가지고 있음.
- 상호 작용을 위한 표준 API의 부족
- 아이콘, 이미지, 다이어그램 및 공간 관계와 같은 중요한 정보는 직접적으로 언어로 전달하기 어려움.
- 웹 페이지와 같은 텍스트 기반 GUI에서도 캔버스 및 iframe과 같은 요소는 HTML을 통해 기능을 파악하기 어려움.
- 이 논문에서는 GUI 이해와 계획을 전문으로 하는 VLM, CogAgent를 제시함.
- cross-modality tasks는 다양한 모달리티(예: 시각, 청각, 언어 등)를 포함하는 작업으로 여러 가지 입력 형식을 처리하고 이를 결합하여 작업을 수행함. (예: 비디오에서 음성과 이미지를 동시에 처리하여 캡션을 생성하는 작업)
- Training Data
- 대부분의 현재 VLM은 웹 이미지로 이루어진 LAION과 같은 데이터셋에서 사전 훈련됨.
- 그러나 GUI 이미지는 다른 분포를 가지고 있기 때문에 GUI 및 grounding data를 추가하여 훈련 데이터 보충.
- OCR에 관한 대규모 주석이 달린 데이터셋을 구축함.
- High-Resolution vs. Compute.
- GUI에서는 아이콘과 텍스트가 많이 등장하고, 일반적으로 사용되는 224 x 224 해상도에서는 이를 인식하기 어려움.
- 입력 이미지의 해상도를 높이면? 언어 모델에서는 긴 시퀀스 길이로 이어짐. 이는 과도한 훈련 및 추론 계산을 요구함
- 이를 해결하기 위해 적절한 computational budget 내에서 해상도와 hidden size 의 trade-off를 허용하는 cross attention branch를 적용.
- CogVLM에서 사용된 원래의 largeViT(4.4B)와 small high-resolution cross-module (with image encoder of 0.3B)를 함께 사용하여 시각적 특징 모델링을 제안함.
- CogVLM은 VLM로, 자연어와 이미지를 함께 처리할 수 있는 멀티모달 모델입니다. CogVLM은 대규모 데이터셋인 LAION을 기반으로 사전 훈련되었으며, 자연어 처리와 이미지 인식 작업에 대한 높은 성능을 보입니다. 이 모델은 자연어와 이미지를 함께 처리할 수 있는 능력을 갖추고 있어, 다양한 시각적 작업에 활용될 수 있습니다.
- 실험 결과
- GUI understanding과 decision-making에서 우수한 성적을 거둠.
- VQA 테스크에 대해서도 뛰어난 성능을 보여줌.
- high & low resolution branch가 독립적으로 동작함으로 인해 연산량을 크게 낮출 수 있었음.
( 1120 × 1120 사이즈 이미지를 처리하는 연산량(FLOP)은 490 × 490 입력을 처리하는 CogVLM-17B 연산량의 절반 미만 )
Method
Architecture
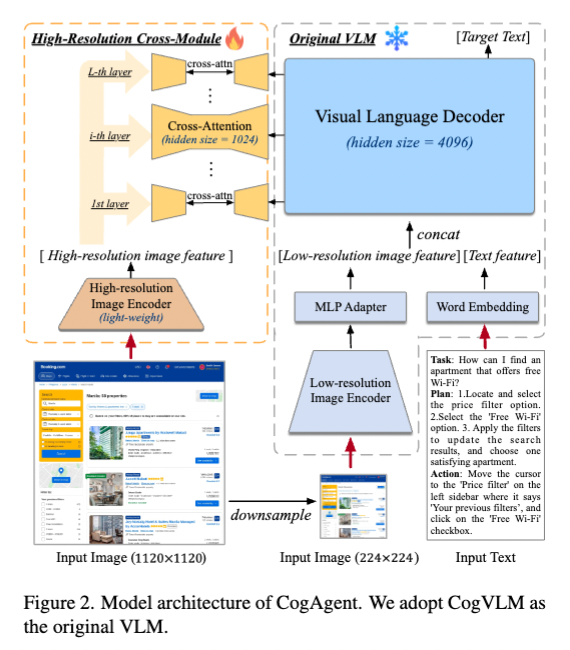
- pre-trained VLM(Visual-Language Model : 이미지와 텍스트를 함께 이해하고 처리하는 모델)을 기반으로 모델을 구축하고(이미지의 오른쪽 부분), 고해상도(high resolution) 입력을 처리하기 위해 cross attention module(서로 다른 두 개의 시퀀스를 다루는 attention-module)을 추가함.(이미지의 왼쪽 부분).
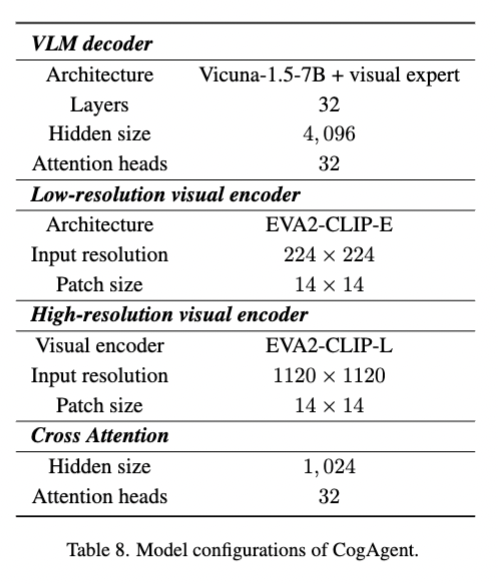
- 기본 VLM으로 CogVLM-17B을 사용, 이는 오픈 소스이자 SOTA vision-language 모델.
- 저해상도 이미지(224×224 픽셀)의 인코더로 EVA2-CLIP-E를 사용하고,
(고해상도 이미지를 처리하기 위한 경량화된 비전 인코더)- 인코더를 통해 나온 벡터를 MLP Adapter에 통과시켜 VLM 디코더의 feature space에 mapping해줌.
- 디코더는 pre-trained language model로, visual expert model을 사용하여 시각 및 언어 기능을 심층적으로 융합할 수 있도록 함.
- 디코더는 4096의 hidden size를 가지고, 저해상도 이미지로부터 획득한 벡터와 input text를 embedding한 벡터를 concat한 것을 입력으로 받음.
- 기존의 CogVLM은 상대적으로 낮은 해상도(224 또는 490)의 이미지만 수용할 수 있어서, 컴퓨터 또는 스마트폰의 화면 해상도가 일반적으로 720p(1280 × 720 픽셀) 이상인 GUI의 요구를 충족시키기 어려움.
- 고해상도 이미지가 지나치게 많은 시간과 메모리를 필요로 하기 때문
- CogVLM도 입력 이미지의 사이즈가 커지면 시간,메모리 오버헤드가 발생
- 이를 해결하기 위해 high resolution cross module을 제안
- 이 모듈은 고해상도 이미지에 대한 효율성을 유지하는 데 더불어 다양한 시각-언어 모델 아키텍처에 유연한 적응성을 제공
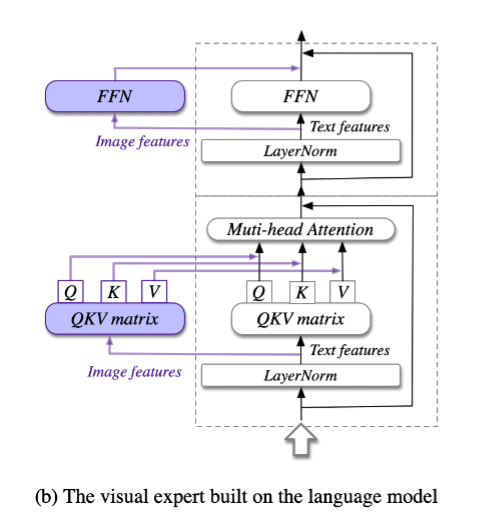
high resolution cross-module
- EVA2-CLIP-L의 vision encoder(0.30B)를 사용 (경량화된 pre-trained vision encoder)
- 문서 OCR과 같은 텍스트 중심 작업에 대한 VLM은 더 작은 hidden size가 필요
이는 텍스트 관련 기능이 더 작은 숨겨진 크기를 사용하여 효과적으로 캡처될 수 있음 - 1120 × 1120 이미지를 받고, 더 작은 hidden size의 크로스 어텐션을 사용하여 VLLM 디코더의 모든 레이어에서 고해상도 이미지 기능을 융합하여 계산 비용 절감
- 구체적으로, 입력 이미지는 1120 × 1120 및 224 × 224로 크기를 조정하고 high resolution cross module과 low resolution branch에 이미지 인코더로 인코딩되어 image feature sequence X_hi 및 X_lo로 병렬 처리.
- visual-language decoder의 변경 사항은 X_hi와 디코더 레이어의 hidden state 간에 cross attention을 통합하는 것.
- x_in은 low-resolution 이미지로부터의 벡터와 input_test로 부터의 embedding 벡터를 결합한 것
- residual connection 테크닉 적용
- x'_i와 high-resolution 이미지로 부터 획득한 벡터를 cross attention함.

pretraining
해상도 이미지에서 다양한 크기, 방향 및 글꼴의 텍스트를 인식하는 능력, 이미지 내 텍스트 및 객체의 바닥에 대한 이해 능력, 그리고 웹 페이지와 같은 GUI 이미지에 대한 전문적인 이해 능력을 위한 사전 훈련 데이터를 세 가지 부분으로 나누었음.
1. Text recognition.
(1) Synthetic rendering with text from language pre-training dataset(80M)
(LAION-2B [32]의 다양한 이미지 배경에서 글꼴, 크기, 색상 및 방향이 다른 텍스트를 포함)
-> Nougat과 동일한 데이터 증강 기법을 적용
(2) Optical Character Recognition (OCR) of natural images (18M)
COYO와 LAION-2B에서 이미지를 수집하고 Paddle-OCR을 사용하여 텍스트와 경계 상자를 추출하고 텍스트 상자가 없는
이미지 필터링. -> 회전 및 뒤집기 데이터 증강(텍스트 인식 능력)
(3) Academic documents (9M)
텍스트, 공식 및 테이블을 포함하는 이미지-텍스트 쌍 -> Nougat과 동일한 데이터 증강 기법을 적용
Nougat은 LaTeX 소스 코드에서 이미지와 텍스트를 추출하여 이미지-텍스트 쌍을 생성하는 방식으로 데이터를 구축합니다. 이러한 데이터를 사용하여 모델을 사전 훈련시키기 위해, Nougat은 다양한 데이터 증강 기법을 적용합니다. 이러한 증강 기법은 이미지를 변형시켜 다양한 시각적 상황을 모방하도록 합니다. 예를 들어, 이미지를 회전시키거나 뒤집는 등의 변형을 적용하거나, 이미지에 노이즈를 추가하거나, 이미지를 압축하거나, 이미지를 왜곡시키는 등의 방식으로 데이터를 증강합니다.
2. Visual grounding
GUI agent는 이미지 내의 다양한 요소를 정확하게 이해하고 위치를 파악할 수 있어야하기 때문에 pre-training 단계에 다양한 groud data를 포함. (ground data: 이미지 내의 객체나 텍스트 등을 지칭하는 바운딩 박스와 같은 정보를 포함하는 데이터)
CogVLM에서 사용한 LAION-115M에서 샘플링된 이미지-캡션 쌍으로 구성된 40M 개의 visual ground dataset을 사용.
웹 페이지 요소에 대한 ground dataset 수집.
3. GUI imagery
(1) GUI Referring Expression Generation (REG)
스크린샷의 지정된 영역을 기반으로 DOM (Document Object Model) 요소에 대한 HTML 코드를 생성
(2) GUI Referring Expression Comprehension (REC)
주어진 DOM 요소에 대한 경계 상자를 생성하는 작업을 수행
CCS400K (Common Crawl Screenshot 400K) 데이터셋을 구축 ( 최신 Common Crawl 데이터에서 URL을 추출한 후 40만 개의 웹 페이지 스크린샷을 캡처), Playwright1을 사용하여 DOM 요소와 해당 렌더링된 상자를 컴파일하여 1억 4천만 개의 REC 및 REG 질문-답변 쌍으로 데이터셋을 보강하여 GUI 요소의 이해를 높임.
Multi-task Fine-tuning and Alignment
다양한 작업에 대한 성능을 향상시키고, GUI 환경에서 유저의 지시를 잘 따르는 것을 보장하기 위해 다양한 task에 대해 fine-tuning 진행. 모바일 폰과 컴퓨터에서 2,000개 이상의 스크린샷을 수집하고, 각각의 스크린 요소, 잠재적인 작업 및 작업 방법을 질문-답변 형식으로 직접 주석을 달아 사용.
웹 및 안드로이드 동작에 초점을 맞춘 Mind2Web 및 AITW 데이터셋을 활용
VQA 데이터셋 활용
3. experiements
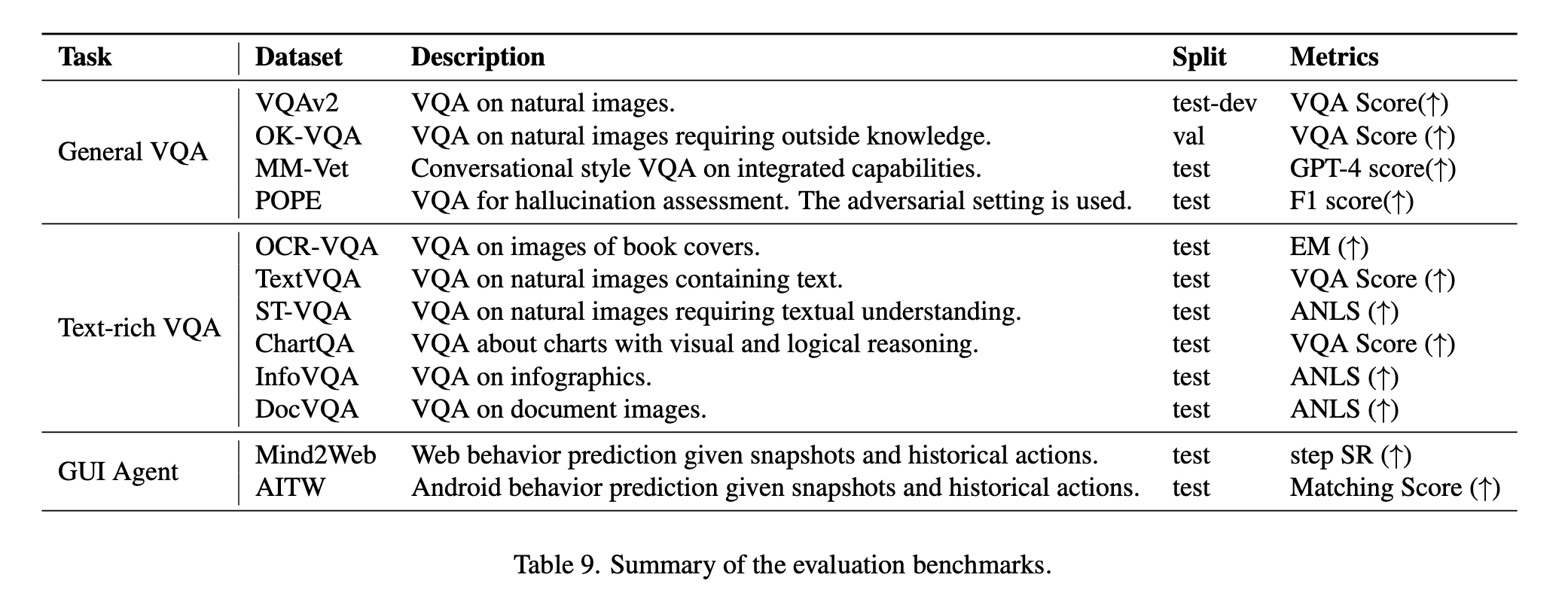
GUI Agent: Computer Interface

GUI Agent: Smartphone Interface

MM-Vet : 멀티모달 모델의 능력과 복잡한 작업에 대한 일반화 성능을 평가하기 위한 벤치마크
POPE_adv(adversarial evaluation) : 모델들의 취약성을 평가하기 위한 벤치마크

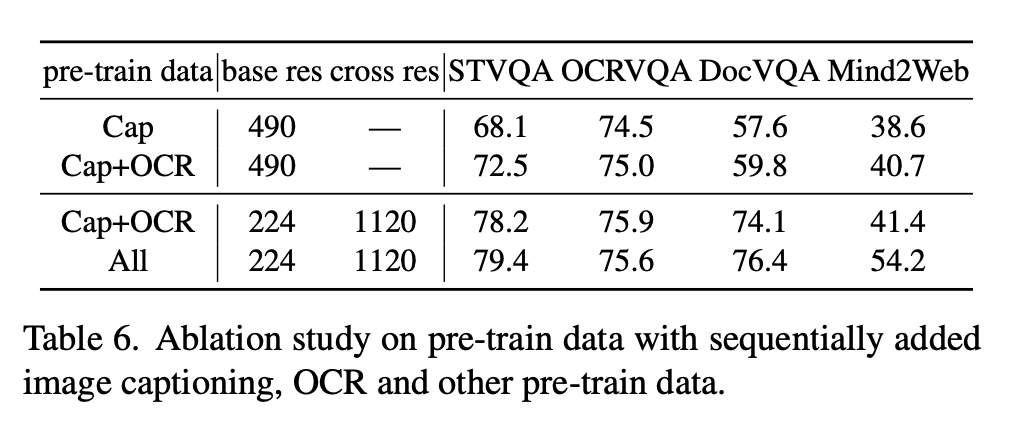
4. ablation study
- 고해상도 이미지를 처리할 때, cross-module을 사용하는 것과 그렇지 않은 것의 연산량을 FLOPs로 비교

- pre-train Data : 데이터의 영향력을 평가
"Cap": 이미지 캡션 데이터를 기반으로 한 사전 훈련 데이터로 이미지에 대한 설명이나 캡션을 포함
"Cap+OCR": "Cap"에 OCR(광학 문자 인식) 데이터를 추가한 것(OCR 데이터는 자연 이미지에서 텍스트를 추출하여 모델이 이미지 내의 텍스트를 이해하고 처리할 수 있도록 하기 위함)
"All": "Cap+OCR"에 GUI 및 그라운딩 데이터를 추가한 것. GUI 데이터는 그래픽 사용자 인터페이스 이미지에 대한 정보를 포함하며, 그라운딩 데이터는 이미지 내의 객체나 텍스트 등을 지칭하는 바운딩 박스와 같은 정보를 포함.