
티스토리 뷰
Abstract
Large Language Model
: 언어를 이해하고 생성할 수 있지만, hallucination이 존재하며 정확하지 않은 output을 제공하는 경향이 있음.
이를 해결하는 방법?
외부 정보를 검색하여 LLMs를 보강하는 것!
그러나 대부분의 Retrieval Augmented LM은 입력을 기반으로 정보를 한 번만 검색하는 retrieve-and-generate setup 사용.
긴 텍스트를 생성할 때는 계속해서 정보를 수집해야 하는데, 기존의 검색 보강 언어 모델은 입력을 기반으로 한 번만 정보를 검색하기 때문에 이러한 상황에서는 제한적일 수 있음.
이 논문에서는 active retrieval augmented generation을 제안
FLARE : Forward-Looking Active REtrieval augmented generation
예측된 다음 문장을 반복적으로 사용하여 future content를 예측하는데, low-confidence 토큰이 있을 경우 future content를 예측하기 위한 다음 예측 문장을 반복적으로 활용하여 관련 문서를 검색하여 문장을 재생성한다.
low-confidence tokens는 언어 모델이 생성하는 문장에서 확률이 낮은 토큰을 의미하며, 이러한 토큰은 언어모델이 해당 정보를 잘 모르거나 잘못 이해하고 있는 경우가 많아서 FLARE는 이를 쿼리로 사용하여 관련 문서를 검색하고, 결과를 활용하여 보다 정확한 문장을 생성하도록 도움을 준다.
Introduction
Generative Language Models?
hallucination, 부정확한 output을 생성하는 경향이 있음.
hallucination을 해결하기 위해 외부 자원에서 관련 정보를 검색하는 것을 LM에 추가할 수 있음.
Retrieval augmented LMs는 일반적으로 retrieve-and-generate setup을 사용함.
사용자의 입력을 기반으로 문서를 검색한 다음, 검색한 문서를 기반으로 답변을 생성
이러한 single-time retrieval augmented LM은 QA같은 짧은 형식의 태스크에서는 일반 LM보다 뛰어나다.
single-time retrieval augmented LM 은 일반 LM보다 성능이 뛰어나며, 특히 사용자의 입력에서 정보 요구가 명확한 QA(factoid question Answering)와 같은 짧은 형식의 task인 경우, 사용자의 입력에 대하여 한 번만 검색하는 것으로도 충분히 좋은 output을 제공할 수 있다.
short-form generation과는 달리 long-form generation은 입력만으로는 명확한 정보를 제공할 수 없어 추가적인 정보가 필요함.
논문, 에세이, 책과 같은 콘텐츠를 작성하는 과정에서 사람들이 정보를 점차적으로 수집하는 것과 유사하게, LM을 통한 장문 생성은 생성 과정 전반에 걸쳐 여러 개의 지식을 요구한다.
예를 들어 특정 주제에 대한 요약을 생성하기 위해서는 주제를 기반으로한 한 번의 검색만으로 모든 세부 사항을 다룰 수 없다.
따라서 생성 중에 필요한 세부 사항을 생성하는 과정에서 추가 정보를 검색하는 것이 중요하다.
이전 시도
- 이전에 생성된 내용을 기반으로 일정 간격으로 추가 정보를 검색
: 언어 모델이 미래에 생성할 내용을 정확하게 반영하지 않거나 부적절한 시점에 정보를 검색할 수 있음.
- multihop QA에서는 전체 질문을 하위 질문으로 분해하고 각각의 하위 질문을 사용하여 추가 정보를 검색
Multihop QA는 복잡한 질문에 대답하기 위해 정보 검색과 추론을 통해 구성된 질문 응답 시스템으로, 단일 단계의 정보 검색이나 추론으로는 해결하기 어려운 복잡한 질문에 대답하기 위해 여러 단계의 정보 검색과 추론이 필요한 경우에 사용된다.
"한국에서 가장 높은 산은 어디인가요?"와 같은 질문이 있을 때, 이를 하위 질문으로 분해하여 "한국에서 가장 높은 산의 이름은 무엇인가요?"와 "그 산의 높이는 얼마인가요?"와 같은 하위 질문을 생성하여 각각의 답변을 검색하고, 이를 조합하여 최종적인 답변을 생성할 수 있다.
Q. 생성 과정 전반에 걸쳐 언제, 어떤 정보를 검색할지 적극적으로 결정하는 retrieval augment LM을 만들 수 있을까?
이는 다양한 장문 생성 작업에 적용될 수 있을까?
LM이 정보가 부족할 때에만 검색해야 하며, 수동적인 retrieval augment LM에서 발생하는 불필요한 검색은 피해야 한다.
LLM은 잘 보정되는 경향이 있고, 낮은 확률과 신뢰도를 가진 예측은 해당 예측이 지식의 부족을 나타내기 때문에, LM이 낮은 확률 토큰을 생성할 대만 검색할 수 있도록 능동적 검색 전략을 적용한다.
Active Retrieval의 목표는 future generations에 도움이 되는 것이기 때문에 무엇을 검색할지 결정할 때, 앞으로 LM이 생성하려는 내용을 고려하는 것이 중요하다.
따라서, 우리는 임시로 다음 문장을 생성하여 미래를 예측하고, 이를 쿼리로 사용하여 관련 문서를 검색한 후, 검색된 문서를 기반으로 다음 문장을 재생성하는 것을 제안한다.
이 두가지 측면을 결합하여, 우리는 Forward-Looking Active REtrieval augmented generation(FLARE)을 제안한다.
FLARE는 임시로 다음 문장을 반복적으로 생성하고 낮은 확률 토큰이 포함되어 있을 때 관련 문서를 검색하고, 끝에 도달할 때 까지 다음 문장을 재생성한다.

FLARE는 추가적인 학습 없이 기존 LM의 inference에 적용할 수 있음
text-davinci-003에서 FLARE 방법의 효과를 평가.
multihop QA (2WikiMultihopQA), 상식적 추론 (StrategyQA), 장문형 QA (ASQA), 그리고 오픈 도메인 요약 (WikiAsp)과 같이 긴 결과물을 생성하는 4가지 다양한 작업/데이터셋에서 FLARE를 평가합니다.
모든 task에서 FLARE는 우수하거나 경쟁력 있는 성능을 보여주며, 이 방법의 효과와 일반화 가능성을 보여준다.
2. Retrieval Augmented Generation
2.1 Notations and Definitions
user input : $x$
document corpus $D = \left\{d_i \right\}_{i=1}^{|D|} $
corpus에서 검색된 정보를 활용하여 m개의 문장 또는 n개의 토큰을 포함하는 답변을 생성하는 것.
$y = [s_1, s_2, ..., s_m] = [w_1, w_2, ..., w_n]$
retrieval augmented LM에서 일반적으로 LM은 query q에 대한 문서 리스트 $D_q = ret(q)$를 검색할 수 있는 retriever와 짝을 이룬다.
*ret(q)는 질의 q에 대한 문서 목록을 검색하는 리트리버 함수를 나타냅니다.
LM은 user input $x$와 검색된 문서 $D_q$ 에 영향을 받아 답변을 생성한다.
우리는 언제, 무엇을 검색할지 결정하는 다양한 방법을 조사하기 위해 기존 방법을 따르며, 공정한 비교를 위해 기준선과 우리 방법 모두에 대해 생성을 돕기 위해 사용자 입력 앞에 검색된 문서를 먼저 추가한다.
$y=LM\left ( \left [ D_q, x \right ] \right )$
[·, ·]는 지정된 순서를 따르는 연결(concatenation)을 나타냄.
2.2 Single-time Retrieval Augmented Generation
사용자 입력을 직접 query로 사용하여, 한 번에 완전한 답변을 생성하는 것이다.
$y=LM\left ( \left [ D_x, x \right ] \right )$
2.3 Active Retrieval Augmented Generation
retrieval을 사용하여 long-form 문장을 생성하기 위해, 우리는 Active Retrieval Augmented Generation을 제안한다.
이는 검색과 생성을 반복하여 생성 과정에서 언제 무엇을 검색할지 능동적으로 결정하는 프레임워크이다.
형식적으로, t(t ≥ 1)단계에서 retrieval query $q_t$는 user input $x$와 이전에 생성된 출력 $y_{<t} = [y_0, y_1,...,y_{t-1}]$에 기반하여 구성된다. $q_t = qry(x,y_{<t})$
t=1 일 때, $y_{<1} = \o$ 이전 생성은 비어있기 때문에, user input이 $q_1 = x$로 사용된다.
검색된 문서 $D_{q_t}$가 주어지면, LM은 끝날 때 까지 답변을 계속 생성한다.
$y_t = LM\left ( \left [ D_{q_t},x,y_{<t} \right ] \right )$
$y_t$는 t에서 생성된 토큰으로 LMs의 입력으로 문서 $D_{q_t}$, user input $x$, 이전 생성 $y_{<t}$의 concatenation이다.
우리는 이전에 검색된 문서를 삭제하고, 다음 생성을 조건부로 만들기 위해 현재 단계에서 검색된 문서만 사용하여 LM의 입력 길이 제한을 넘지 않도록 한다.
3. FLARE: Forward-Looking Active REtrieval Augmented Generation
- LM은 불필요하거나 부적절한 검색을 피하기 위해, 필요한 지식이 없을 때에만 정보를 검색해야한다.
- 생성 과정에서 다음에 생성될 내용을 예측하고, 그에 맞는 검색 질의를 생성하여 필요한 정보를 검색해야한다.
2가지 FLARE 방법을 제안 : FLAREinstruct, FLAREdirect
3.1 FLARE with Retrieval Instructions : FLAREinstruct
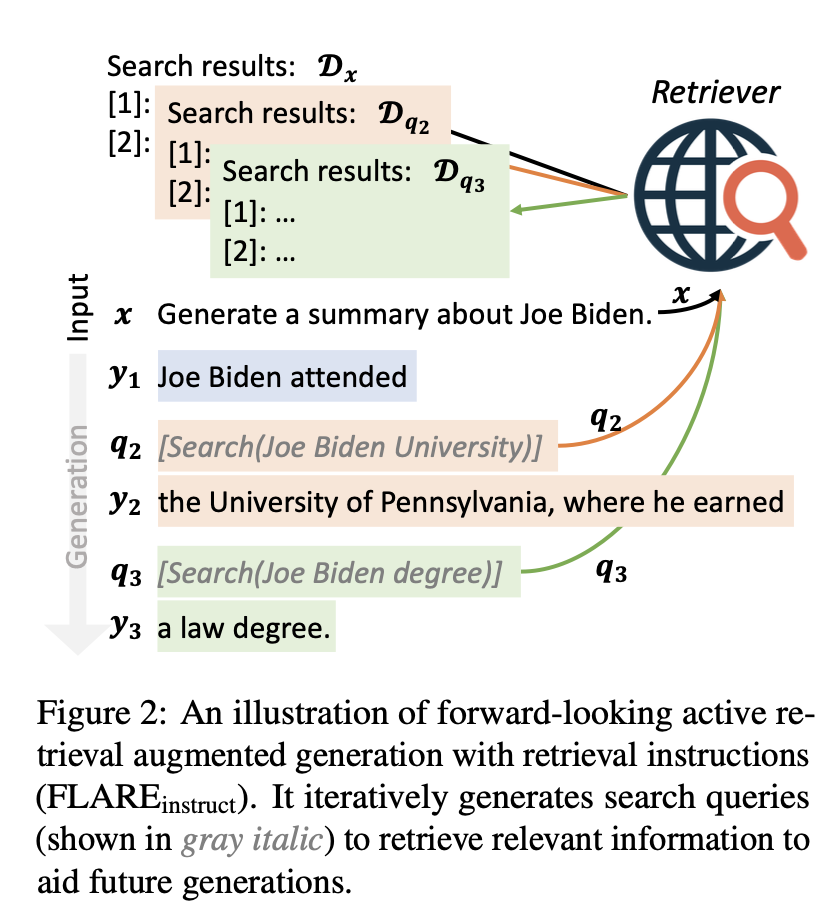
LM이 답변을 생성하는 동안 필요한 정보를 검색하기 위해 검색 쿼리를 생성하도록 유도하고, 이를 위해 retrieval-encouraging instructions을 사용하여 답변을 생성합니다.
정보 검색이 필요한 경우 "[Search(query)]"와 같은 형식으로 검색 쿼리를 생성합니다.
예시 )
“The colors on the flag of Ghana have the following meanings. Red is for [Search(Ghana flag red meaning)] the blood of martyrs, ...”

GPT-3.5 API를 사용하여 few-shot prompting을 진행한다.
Skill 1. : LM이 search query 생성하는 방법을 안내하는 instruction과 검색 관련 예시로 구성
Skill 2. : LM이 downstream task를 수행하는 방법을 안내하는 instruction과 하위 작업 관련 예시로 구성
test case : LM에게 skill1과 skill2를 통해 task를 수행하는 동안 search query를 생성하도록 요청
그림 2에서, LM이 "[Search(query)]"를 생성하면, 기존 생성은 멈추고 query terms를 사용하여 관련 문서를 검색하며, 이는 사용자 입력 앞에 추가되어 앞으로의 생성을 돕는다. 다음 search query가 생성되거나 끝이 나기 전 까지 반복.
3.2 Direct FLARE : FLAREdirect
Black-box LM을 fine tune 할 수 없기 때문에, "retrieval instructions"를 통해 생성된 쿼리는 LM이 내부적으로 어떻게 생성되었는지에 대한 신뢰성을 보장하기 어려울 수 있다.
* 블랙박스 LM은 내부 동작이나 구조에 대해 외부에서 직접적으로 액세스할 수 없는 머신 러닝 모델을 가리킨다.. 즉, 입력과 출력 간의 관계는 알려져 있지만 내부적으로 어떻게 작동하는지에 대한 정보는 제한적이거나 알려지지 않은 모델을 의미.
LMs의 생성을 직접 search queries로 사용하며, future topic에 대한 정보를 얻기 위해 반복적으로 다음 문장을 생성하고, 불확실한 토큰이 있으면 관련 문서를 검색하여 다음 문장을 재생성한다.
3.2.1 Confidence-based Active Retrieval
t 단계에서 먼저 검색된 문서에 의존하지 않고 임시 문장$\hat{s}_t = LM\left ( \left [ x, y_{<t} \right ] \right )$을 생성한다.
임시로 생성한 다음 문장 $\hat{s}_t$를 기반으로 검색을 시작할지, 쿼리를 구성할지 결정한다.
LM이 $\hat{s}_t$를 생성할 시에 해당 문장에 대해 높은 확신을 가지고 있었다면, 추가 정보를 검색하지 않고 그것을 사용하지만, 그렇지 않다면 $\hat{s}_t$를 사용하여 search queries $q_t$를 구성하여 관련 문서를 검색한 후에 다음 문장 $s_t$를 재생성한다.
낮은 확률/신뢰도는 LM이 해당 정보를 제대로 알고 있지 않아서, 검색이 필요하다는 것이기 때문에, $\hat{s}_t$의 어떤 토큰의 임계값 θ ∈ [0, 1] 보다 낮은 확률을 가지고 있다면, 검색을 시작한다. ( θ = 0이면 검색을 하지 않음, θ = 1은 매 문장마다 검색을 진행.)
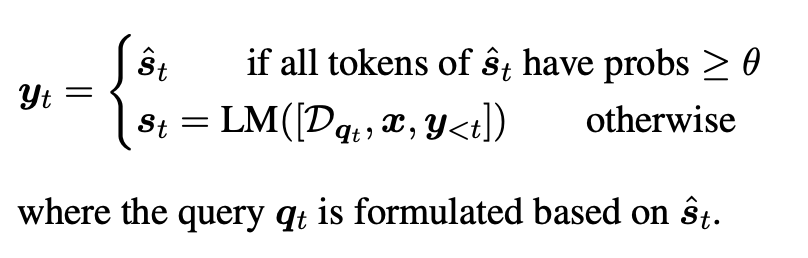
3.2.2 Confidence-based Query Formulation
다음 문장 $\hat{s}_t$를 직접 search query $q_t$로 사용하여 검색을 진행할 수 있음.
6.2절에서 다음 문장을 사용하여 검색하는 것이 이전 문맥을 사용하는 것보다 훨씬 더 나은 결과를 얻을 수 있다는 것을 보여줌.
그러나 이 방법은 그 안에 포함된 오류를 계속 전달할 위험이 있다.
3.2.1에서는 LM이 임시 다음 문장을 생성한 후, 해당 문장에 대한 신뢰도를 확인하고, LM이 해당 문장에 대해 확신을 가지고 있지 않을 경우 search query를 생성하여 관련 문서를 검색하고, 그 후에 다시 다음 문장을 생성하는 방법
3.2.2에서는 검색을 수행하기 위해 LM이 다음 문장을 직접 쿼리로 사용하는 방법. 이 방법은 LM이 다음 문장을 직접적으로 검색 쿼리로 사용함으로써 검색 결과를 개선할 수 있지만, 잘못된 정보가 포함되어 있을 경우 해당 오류를 계속 전파할 수 있는 위험이 있음.
예를 들어, LM이 "Joe Biden은 펜실베이니아 대학교에 다녔다"라는 문장을 생성했지만, 실제로는 "Joe Biden은 델라웨어 대학교에 다녔다"는 올바른 사실이 있는 경우, 이 잘못된 문장을 검색 쿼리로 사용하면 잘못된 정보를 검색할 수 있음.
Figure 3에서 설명된 두 가지 방법으로 이 문제를 해결할 수 있다.

- Masked sentences as implicit queries.
첫 번째 방법은 $\hat{s}_t$에서 확률이 β ∈ [0, 1] 이하인 낮은 신뢰도 토큰을 마스킹하는 것입니다.
β 값이 클 수록, 낮은 신뢰도의 토큰이 더 많이 마스킹되어 검색 정확도가 향상됩니다.
- Generated questions as explicit queries.
$\hat{s}_t$에서 신뢰도가 낮은 구간을 대상으로 명시적인 질문을 생성하는 것이다.
예를 들어, LM이 "Joe Biden은 펜실베이니아 대학교"에 대해 불확실한 경우 "Joe Biden은 어떤 대학교에 다녔나요?"와 같은 질문은 관련 정보를 검색하는 데 도움이 될 수 있다.
먼저 $\hat{s}_t$에서 β 이하의 확률을 가진 모든 구간을 추출한다.
추출된 각 구간 $z$에 대해, gpt-3.5-turbo로 해당 구간으로 답변할 수 있는 질문 $q_t, z$를 생성한다.

생성된 질문을 각각 사용하여 검색을 수행하고, 반환된 문서를 하나의 목록을 합친다.
LM이 이전에 생성한 문장에서 언급한 개념에 대한 정보를 찾기 위해 검색을 수행하고, 반환된 문서들을 하나의 목록으로 합치면, 이후 생성 작업에서 LM이 이 목록을 참조하여 더 나은 답변을 생성할 수 있다.

3.3 Implementation Details
Base LM
GPT-3.5 text-davinci-003 에서 위의 방법을 반복적으로 쿼리하여 유효성을 검증합니다.
Document corpus and retrievers.
검색과 생성을 통합하는 것에 중점을 두고 있어서, 우리는 쿼리를 입력으로 받아 관련 문서 목록을 반환하는 off-the-shelf retrievers를 사용한다.
Wikipedia의 경우 Wikipedia dump와 retriever로 BM25를 사용하고,
open-web의 경우 retriever로 Bing 검색 엔진을 사용한다.
Retrieved document formatting
여러 개의 검색된 문서는 가장 관련성이 높은 문서가 가장 먼저 오고, 그 다음으로 두 번째로 관련성이 높은 문서가 오는 식으로 순서가 정해진다. 그리고 이러한 순서대로 검색된 문서들은 Prompt D.1을 사용하여 사용자 입력의 시작 부분에 추가됩니다.
4. Multi-time Retrieval Baselines
Previous-window

previous-window 접근법은 $l$ 토큰마다 검색을 한다. ($l$은 window size)
이전 window에서 생성된 토큰은 쿼리로 사용된다.
여기서는 $l $= 16을 사용한다. (IC-RALM (Ram et al., 2023) )
Previous-sentence
이전 문장 접근법은 매 문장마다 검색하고 이전 문장을 쿼리로 사용한다.
Question decomposition
LM이 출력을 생성하는 동안 하위 질문을 생성하도록 과제별 예시를 직접 주석을 달았음.
예를 들어, self-ask (Press et al., 2022)는 Prompt D.2를 사용하여 예시에 하위 질문을 수동으로 삽입하고, 테스트 케이스에서 검색은 모델이 하위 질문을 생성할 때 동적으로 트리거됩니다.
앞서 언급한 방법은 생성하는 동안 추가 정보를 검색할 수 있다.
그러나 (1) 이전에 생성된 토큰을 쿼리로 사용하는 것이 LM이 미래에 생성하려는 것을 반영하지 않을 수 있음. (2) 고정된 간격으로 정보를 검색하는 것은 부적절한 지점에서 발생할 수 있기 때문에 비효율적일 수 있음. (3) 질문 분해 방법은 과제별 프롬프트 엔지니어링이 필요함.
5. Experimental Setup
Radford et al. (2019), Brown et al. (2020), Liu et al. (2023)의 연구를 참고하여, 소수의 데이터를 사용한 상황 속 학습을 통해 4가지 다양한 knowledge-intensive tasks에서 FLARE의 효과를 평가를 진행.
(FLARE는 명시적으로 명시되지 않은 경우 FLAREdirect를 의미)
Multihop QA
- Multihop QA의 목표는 정보 검색과 추론을 통해 복잡한 질문에 대한 답변을 제공하는 것으로 2WikiMultihopQA 사용
Commonsense reasoning
- Geva et al. (2021)의 StrategyQA 사용.(답변이 예/아니오로 나옴)
Long-form QA
- ASQA (Stelmakh et al., 2022)를 사용.
예를 들어, "필라델피아 이글스는 어디서 홈 경기를 하나요?"라는 질문은 도시, 스포츠 복합체, 또는 경기장에 대한 질문일 수 있음.
따라서, LMs가 답변을 생성하는 동안 올바른 방향을 유지할 수 있도록 간단한 힌트를 제공하는 ASQA-hint라는 또 다른 설정을 생성.
위의 경우에 대한 힌트의 예시 : "이 질문은 특정 위치 또는 장소가 어떤 것을 의미하는지에 대해 모호합니다."
Stelmakh et al. (2022)의 메트릭을 사용했는데, 이는 EM, RoBERTa 기반 QA 점수 (Disambig F1), ROUGE (Lin, 2004) 및 Disambig-F1과 ROUGE를 결합한 전체 점수 (DR)를 포함한다.
Open-domain summarization
- 오픈 웹에서 정보를 수집하여 특정 주제에 대한 포괄적인 요약을 생성하는 것
WikiAsp (Hayashi et al., 2021)를 사용.
예를 들어, "Echo School (Oregon)에 대한 학문 및 역사를 포함한 요약을 생성하십시오."
메트릭은 ROUGE, 명명된 엔티티 기반 F1 및 사실 일관성을 측정하는 UniEval (Zhong et al., 2022)을 포함
6 Experimental Results
6.1 Comparison with Baselines
Overall results.
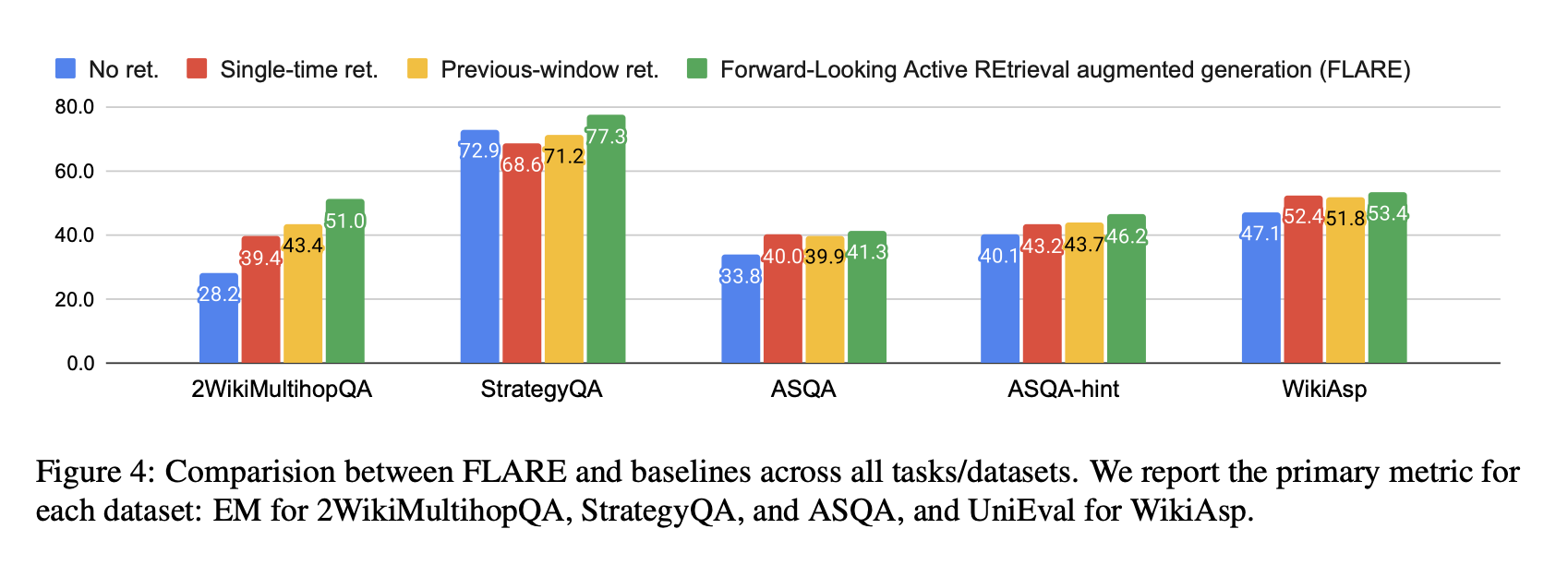
multihop QA가 가장 큰 개선을 보임.
LM이 필요한 정보를 추출하고 추론하여 최종 답변을 생성하는 과정(2-hop 추론 과정)이 명확하게 정의되어 있기 때문에, LM이 주제와 관련된 출력 쉽게 생성할 수 있음.
ASQA와 WikiAsp는 보다 개방적이기 때문에 생성과 평가가 어려움.
ASQA-hint의 개선 정도는 ASQA보다 큼. 모호한 측면을 식별하는 것이 어렵기 때문에, 일반적인 힌트를 제공하는 것이 LM이 주제에 유지되는 데 도움이 될 수 있음.
Thorough comparisons with baselines.
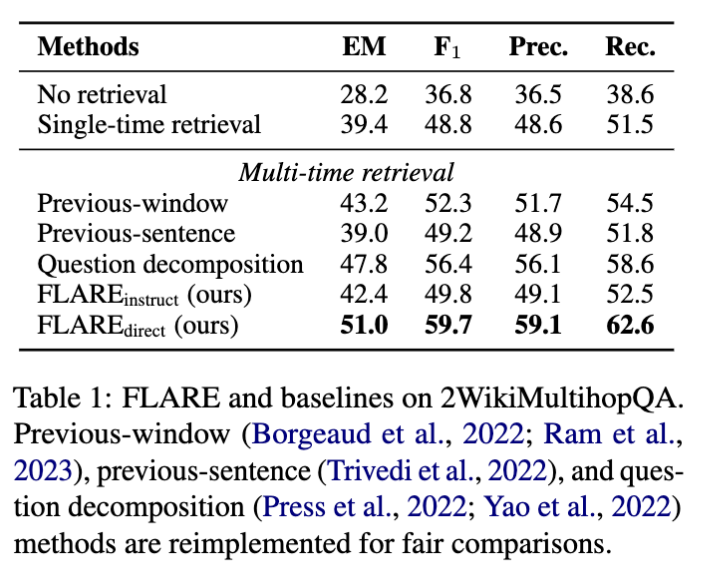
Previous-sentence (이전 문장을 사용하여 검색하는 것)
: 2WikiMultihopQA에서 이전 문장이 다음 문장과 다른 개체 또는 관계를 설명하는 경우가 많기 때문인 것 같음.
Previous-window
: 문장의 첫 번째 절반을 사용하여 두 번째 절반 생성에 유용한 정보를 검색할 수 있음.
Question decomposition
: 하위 질문을 생성하도록 함.


ASQA에서 Single-time retrieval과 Previous-window를 비교하면 Single-time retrieval이 더 나음.
? previous-window가 주제를 정확하게 반영하지 못해서 그런 것으로 추정
사실성을 평가하는 데 중점을 둔 메트릭(예: EM, Disambig-F1, UniEval)이 모든 토큰을 대상으로 계산된 메트릭(ROUGE-L 등)보다 신뢰할 수 있다고 가정
6.2 Ablation Study
Importance of forward-looking retrieval.

이전 문장 기반으로 한 검색 보다 예측한 다음 문장 기반으로 한 검색이 더 효과적임.
Previous & Next 방법 모두 모든 문장을 검색하고 직접 쿼리로 사용.
previous-window 방식을 사용하여 쿼리에 사용하는 토큰의 수를 다르게하여 실험을 진행. 표
이전 문장에서 많은 토큰(> 32)을 사용하면 성능이 저하되며, 이전 컨텍스트가 미래 생성의 의도와 관련이 없을 수 있다는 가설을 확인.
Importance of active retrieval.
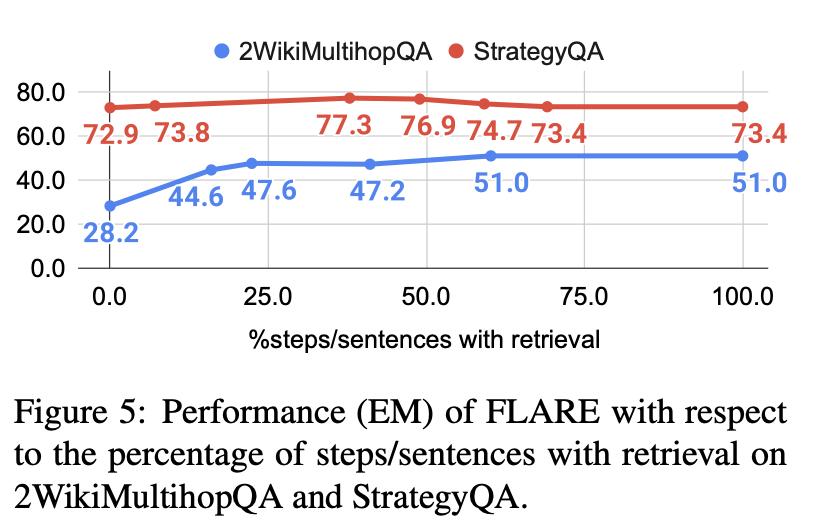
임계값 θ가 성능에 어떤 영향을 미치는지 실험.
임계값 θ를 0에서 1로 조정하며 검색된 단계/문장의 비율을 계산하고, 이를 기반으로 성능을 제시.
문장의 40% ~ 80%에서 검색하는 것이 대부분의 작업/데이터셋에서 좋은 성능을 보이는 것으로 발견.
Effectiveness of different query formulation methods

마스킹 임계값 β로 FLARE의 성능을 비교.
전체 문장을 직접 검색하는 것(β = 0)은 , β > 0 때 보다 점수가 낮음.
: 낮은 신뢰도의 잘못된 토큰이 검색을 방해할 수 있음.
Conclusion
long-form generation with retrieval augmentation
FLARE
예측한 문장을 사용하여 관련 정보를 검색하여 다음 문장을 재생성
Limitations
Wizard of Wikipedia와 ELI5의 경우 FLARE를 통한 성능 개선이 이루어 지지 않았음.
- Wizard of Wikipedia는 지식 중심의 대화 생성 데이터셋으로 출력물이 상대적으로 짧기 때문에(평균 ∼20 토큰), 여러 번의 검색이 필요하지 않을 수 있음.
- ELI5(Explain Like I'm 5)는 어려운 주제를 아이들이 이해할 수 있는 수준으로 설명하는 장문형 QA 데이터셋(긴 질문에 대해 포괄적인 답변을 생성하는 것을 목표)으로, 생성된 답변이 검색과 평가에 기반하여야 하기 때문에, 정확하고 포괄적인 답변을 생성하는 것이 어렵기 때문에 (모델이 실제로 지식을 이해하고 적절한 답변을 생성할 수 있는 능력을 평가하는 것이 어려움) 단일 검색과 FLARE 모두 검색을 사용하지 않는 것과 비교하였을 때 성능 개선이 이루어지지는 않았음.
엔지니어링적인 관점에서, 단순한 구현으로 생성과 검색을 교차로 진행하면 오버헤드와 생성 비용이 증가한다.
LM은 여러 번 활성화되어야 하며(각 검색마다 한 번 - LM이 검색된 문서를 활용하여 새로운 문장을 생성하거나 다음 단어를 예측하기 위해 다시 활성화되어야 한다는 것을 의미),
캐싱이 없는 구현은 검색 후 매번 이전 활성화를 다시 계산해야 한다.(LM이 이전에 생성했던 문장이나 단어를 기억하거나 재사용할 수 없고, 매번 새롭게 계산해야 한다)
이 문제는 검색된 문서 $D_{q_t}와 입력/생성(x/y<t)을 독립적으로 인코딩하는 특수 아키텍처 설계로 잠재적으로 완화될 수 있습니다.
'부스트캠프' 카테고리의 다른 글
| ConTextual Masked Auto-Encoder for Dense Passage Retrieval (0) | 2024.02.19 |
|---|---|
| Visual Instruction Tuning (LLaVA) (0) | 2024.02.04 |
| LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models (3) | 2024.01.21 |
| Do PLMs Know and Understand Ontological Knowledge? (0) | 2024.01.06 |
| [논문 읽기] Fine-Tuning Pre trained Language Models:Weight Initializations, Data Orders, and Early Stopping (0) | 2023.12.25 |